声纹识别的分类
2011/01/05
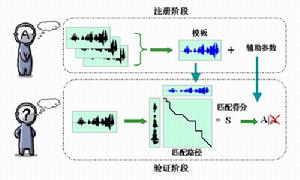
声纹识别(Voiceprint Recognition, VPR),也称为说话人识别(Speaker Recognition),有两类,即说话人辨认(Speaker Identification)和说话人确认(Speaker Verification)。前者用以判断某段语音是若干人中的哪一个所说的,是“多选一”问题;而后者用以确认某段语音是否是指定的某个人所说的,是“一对一判别”问题。不同的任务和应用会使用不同的声纹识别技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。不管是辨认还是确认,都需要先对说话人的声纹进行建模,这就是所谓的“训练”或“学习”过程。CTI论坛报道
| 声纹识别技术:利用人体生物特征进行身份认证 2011-01-05 |
| 声纹识别的原理及其应用 2011-01-05 |
| Nuance:车载信息平台迈入语音时代 2010-12-27 |
| 台达语音:让消费者使用科技就像呼吸般简单自然 2010-12-27 |
| 什么是语音云? 2010-11-26 |